5.9 KiB
Convolutional Networks1
Warning
We apply this concept mainly to
images
Usually, for images, fcnn (short for fully
connected neural networks), are not suitable,
as images have a large number of inputs that is
highly dimensional (e.g. a 32x32, RGB picture
has dimension of 3072 data inputs)2
Combine this with the fact that nowadays pictures
have (the least) 1920x1080 pixels. This makes FCnn
prone to overfitting2
Note
- From here on
depthis the 3rd dimention of the activation voulumeFCnnare just ***traditionalNeuralNetworks
ConvNet
The basic network we can achieve with a
convolutional-layer is a ConvNet.
It is composed of:
input(picture)Convolutional LayerReLUPooling layerFCnn(NormalNeuralNetork)output(classes tags)
Building Blocks
Convolutional Layer
Convolutional Layers are layers that reduce the
size of the computational load by creating
activation maps computed starting from a subset of
all the available data
Local Connectivity
To achieve such thing, we introduce the concept of
local connectivity. Basically each output is
linked with a volume smaller than the original one
concerning the width and height
(the depth is always fully connected)
Filters (aka Kernels)
These are the work-horse of the whole layer.
A filter is a small window that contains weights
and produces the outputs.
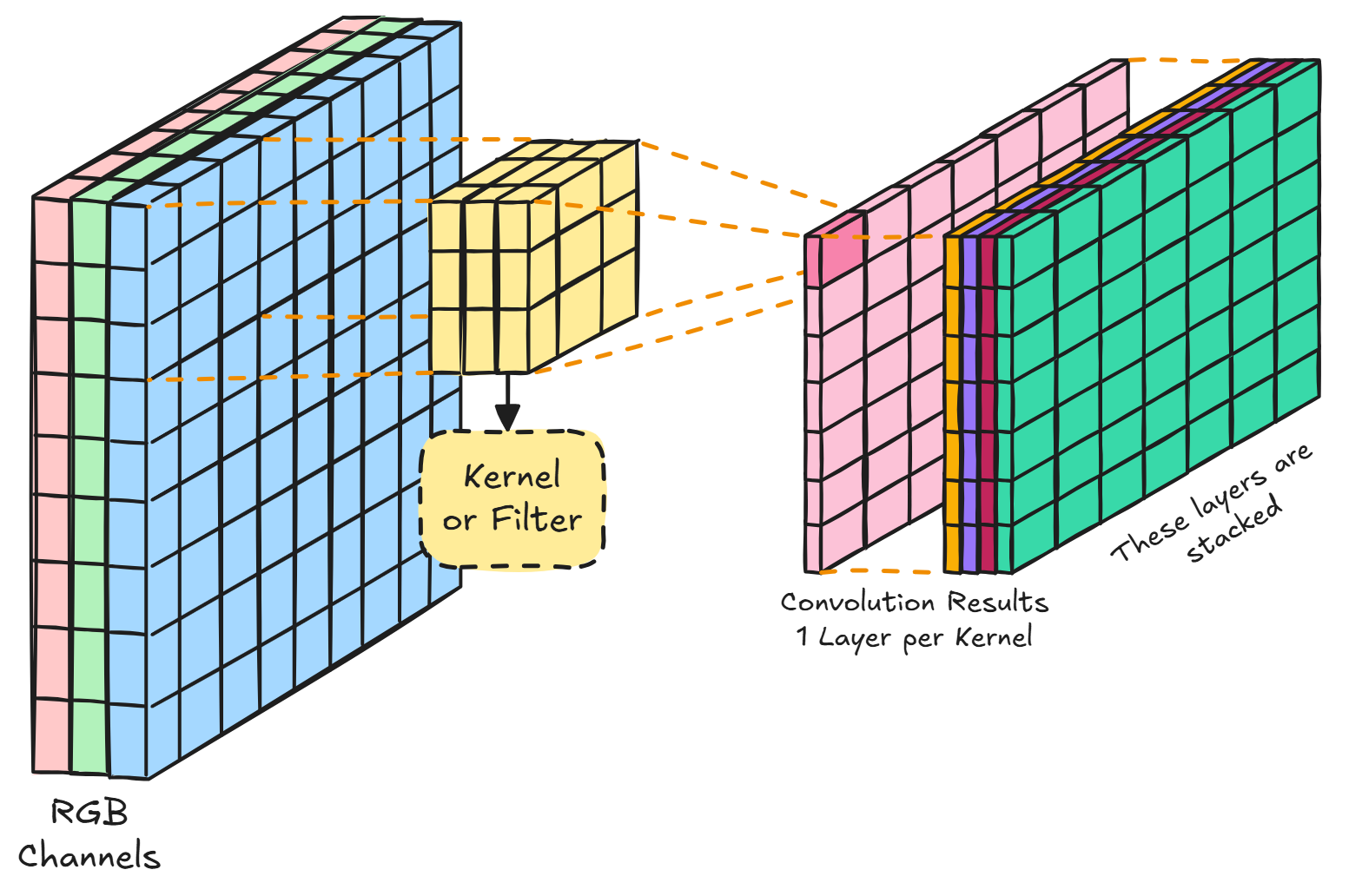
We have a number of filter equal to the depth of
the output.
This means that each output-value at
the same depth has been generated by the same filter, and as such,
any volume shares weights
across a single depth.
Each filter share the same height and width and
has a depth equal to the one in the input, and their
output is usually called activation-map.
Warning
Don't forget about biases, one for each
kernel
Note
Usually what the first
activation-mapslearn are oriented edges, opposing colors, ecc...
Another parameter for filters is the stride, which
is basically the number of "hops" made from one
convolution and another.
The formula to determine the output size for any side
is:
out_{side\_len} = \frac{
in_{side\_len} - filter_{side\_len}
}{
stride
} + 1
Whenever the stride makes out_{side\_len} not
an integer value, we add 0 padding
to correct this.
Note
To avoid downsizing, it is not uncommon to apply a
0padding of size 1 (per dimension) before applying afilterwithstrideequal to 1However, for a fast downsizing we can increment
striding
Caution
Don't shrink too fast, it doesn't bring good results
Pooling Layer3
It downsamples the image without resorting to
learnable-parameters
There are many algorithms to make this layer, as:
Max Pooling
Takes the max element in the window
Average Pooling
Takes the average of elements in the window
Mixed Pooling
Linear sum of Max Pooling and Average Pooling
Note
This list is NOT EXHAUSTIVE, please refer to this article to know more.
This layer introduces space invariance
Receptive Fields4
At the end of our convolution we may want our output to have been influenced by all pixels in our picture.
The amount of pixels that influenced our output is called receptive field and it increases
each time we do a convolution by a factor of k - 1 where k is the kernel size. This is
due to our kernel of producing an output deriving from more inputs, thus influenced by more
pixels.
However this means that before being able to have an output influenced by all pixels, we need to go very deep.
To mitigate this, we can downsample by striding. This means that we will collect more pixel information during upper layers, even though more sparse, and thus we'll be able to get more pixel info over deep layers.
Tips5
1x1filtersmake sense. They allow us to reduce thedepthof the nextvolume- Trends goes towards increasing the
depthand having smallerfilters - The trend is to remove
pooling-layersand use onlyconvolutional-layers - Common settings for
convolutional-layersare:- number of filters:
K = 2^{a}6 - tuple of
filter-sizeFstrideS,0-paddingP:- (3, 1, 1)
- (5, 1, 2)
- (5, 2, whatever fits)
- (1, 1, 0)
- number of filters:
- See ResNet/GoogLeNet