9.6 KiB
Transformers
Transformers are very similar to RNNs
in terms of usage (machine translation, text generation, sequence to
sequence, sentimental analysis, word prediction, ...),
but differ for how they process data.
While RNNs have a recurrent part that computes the input
sequentially, Transformers computes it all at once, making it easier to
parallelize and make it effectively faster despite being quadratically
complex.
However this comes at the cost of not having an infinite context for tranformers. They have no memory, usually12, meaning that they need to resort to tricks as autoregressiveness or fixed context windows.
Basic Technologies
Positional Encoding
When words are processed in our Transformer, since they are processed at once, they may lose their positional information, making them less informative.
By using a Positional Encoding, we add back this information to the word.
There are several ways to add such encoding to words, but among these we find:
- Learnt One:
Use another network to learn how to add a positional encoding to the word embedding - Positional Encoding3:
This comes from "Attention Is All You Need"3 and it's a fixed function that adds alternately the sine and cosine to word embeddings\begin{aligned} PE_{(pos, 2i)} &= \sin{\left( \frac{ pos }{ 10000^{2i/d_{model}} } \right)} \\ PE_{(pos, 2i+1)} &= \cos{\left( \frac{ pos }{ 10000^{2i/d_{model}} } \right)} \end{aligned} - RoPE45:
This algorithm uses the same function as above, but it doesn't add it, rather it uses it to rotate (multiply) vectors. The idea is that by rotating a vector, it doesn't change its magnitude and possibly its latent meaning.
Feed Forward
This is just a couple of linear layers where the first one expands dimensionality (usually by 4 times) of the embedding size, due to Cover Theorem, and then it shrinks it back to the original embedding size.
Self Attention
This Layer employs 3 matrices, for each attention head, that computes Query, Key and Value vectors for each word embedding.
Steps
- Compute
Q, K, Vmatrices for each embedding
\begin{aligned}
Q_{i} &= S \times W_{Qi} \in \R^{S \times H}\\
K_{i} &= S \times W_{Ki} \in \R^{S \times H}\\
V_{i} &= S \times W_{Vi} \in \R^{S \times H}
\end{aligned}
- Compute the head value
\begin{aligned}
Head_i = softmax\left(
\frac{
Q_{i} \times K_{i}^T
}{
\sqrt{H}
}
\right) \times V_{i}
\in \R^{S \times H}
\end{aligned}
- Concatenate all heads and multiply for a learnt matrix
\begin{aligned}
Heads &= concat(Head_1, \dots, Head_n) \in \R^{S \times (n \cdot H)} \\
Out &= Heads \times W_{Heads} \in \R^{S \times Em}
\end{aligned}
Note
Legend for each notation:
H: Head dimensionS: Sentence length (number of tokens)i: head index
Tip
His usually smaller (makes computation faster and memory efficient), however it's not necessary.Here we shown several operations, however, instead of making many small tensor multiplications, it's better to perform one (computationally more efficient) and then split ist result into its components
Cross-Attention
It's the same as the Self Attention, however we only compute Q_{i} for what
comes from the encoder, while K_i and V_i come from inputs coming
from the last encoder:
\begin{aligned}
Q_{i} &= S_{dec} \times W_{Qi} \in \R^{S \times H}\\
K_{i} &= S_{enc} \times W_{Ki} \in \R^{S \times H}\\
V_{i} &= S_{enc} \times W_{Vi} \in \R^{S \times H}
\end{aligned}
Masking
In order to make it sure that a decoder doesn't attent future info for past words, we have masks that makes it sure that information doesn't leak to parts of the networks.
We usually implement 4 kind of masks
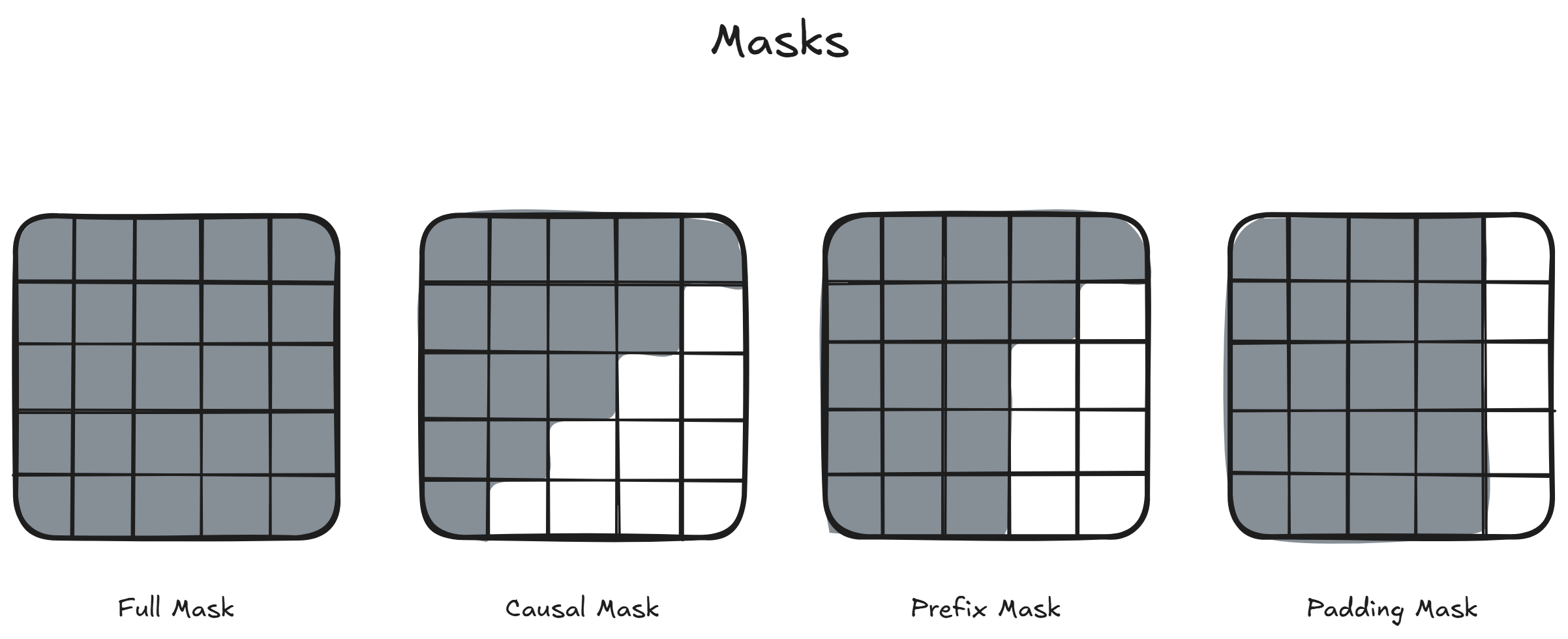
- Padding Mask:
This mask is useful to avoid computing attention for paddings - Full Attention: This mask is useful in encoders. It allows the attention to have a double directed attention by making words on the right add info to words on the left and vice-versa.
- Causal Attention:
This mask is useful in decoders. It denies the attention of words on the right to leak over leftwards ones. In other words, it prevents that future words can affect the past meaning. - Prefix Attention:
This mask is useful for some task in decoders. It allows some words to add info over the past. These words however are not generated by the decoder, but are part of its initial input.
Basic Blocks
Embedder
This layer is responsible of transforming the input (usually tokens) into word embeddings following these steps:
- one-hot encoding
- matrix multiplication to get the desired embedding
- inclusion of positional info
Encoder
It takes meanings from embedded vectors both on the right and left part:
- Self Attention
- Residual Connection
- Layer Normalization
- Feed Forward
- Residual Connection
- Layer Normalization (sometimes it is done before going to self attention)
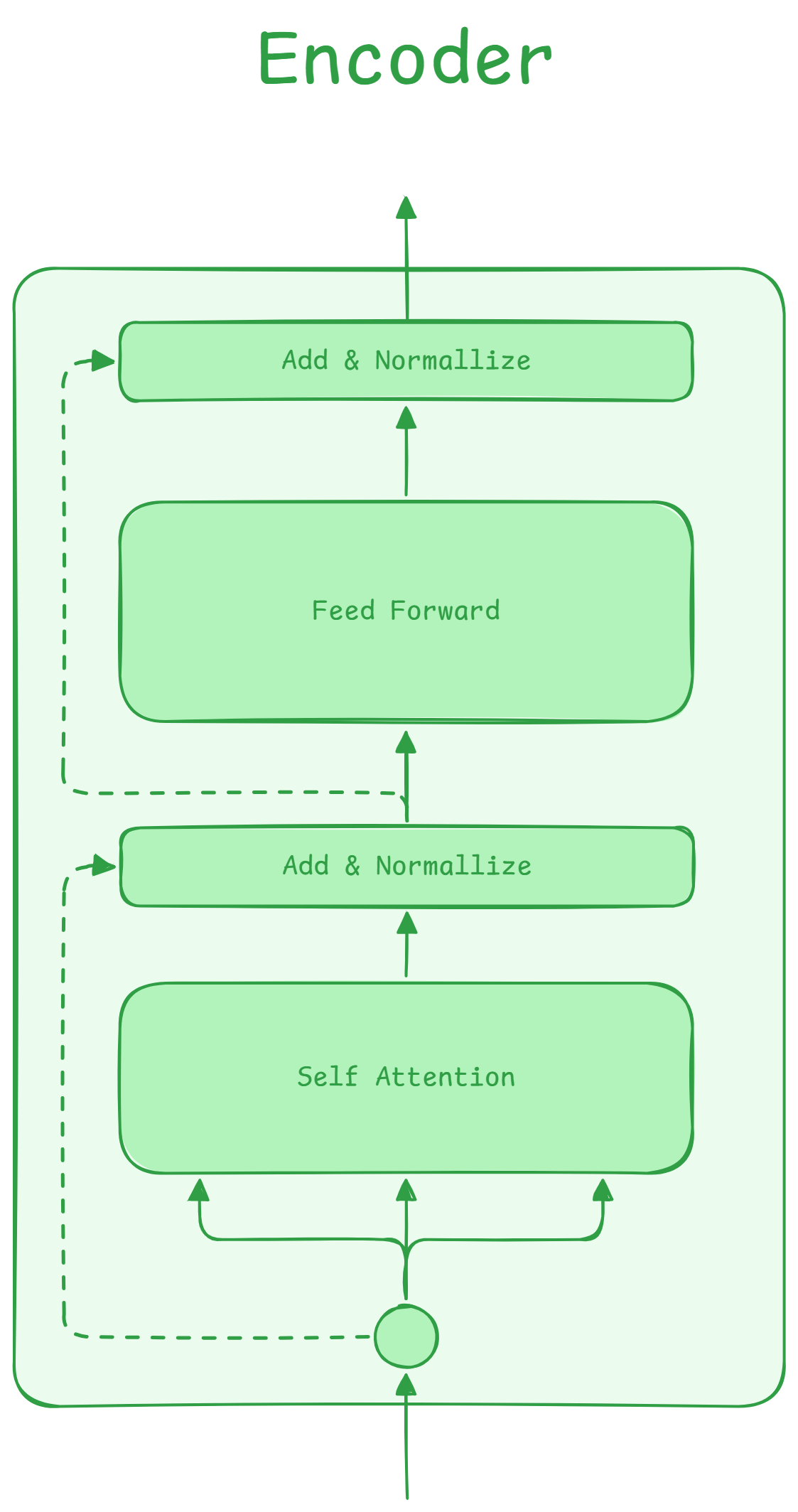
Usually it used to condition all decoders, however, if connected to a
De-Embedding block or other layers, it can be used stand alone to
generate outputs
Decoder
It takes meaning from output embedded vectors, usually left to right, and condition them with last encoder output.
- Self Attention
- Residual Connection
- Layer Normalization
- Cross Attention
- Residual Connection
- Layer Normalization
- Feed Forward
- Residual Connection
- Layer Normalization (sometimes it is done before going to self attention)
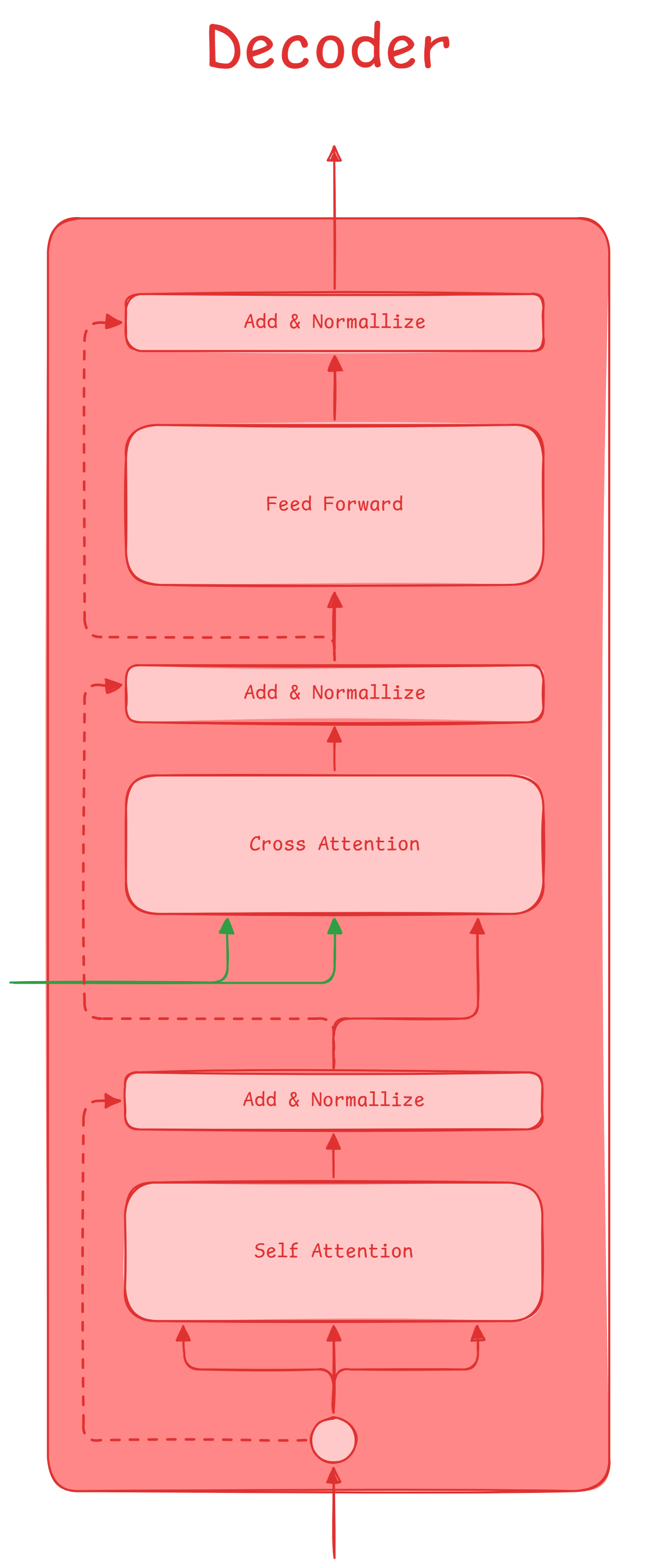
Usually this block is used to generate outptus autoregressively, meaning
that we'll only take out_{k} as the actual output and append it as in_{k+1}
during inference time.
Warning
During train time, we are going to feed it all expected sequence, but shifted by a
starttoken, predicting the whole sequence again.So, it isn't trained autoregressively
De-Embedding
Before having a result, we de-embed results, coming to a known format.
Usually, for text generation, this makes the whole problem a classification one as we need to predict the right token among all available ones.
Usually, for text, it is implemented as this:
- Linear layer -> Go back to token space dimensions
- Softmax -> Transform into probabilities
- Argmax -> Take the most probable one
However, depending on the objectives, this is subject to change
Basic Architectures
Full Transformer (aka Encoder Decoder - Encoder Conditioned)
This architecture is very powerful, but "with great power, comes a great
energy bill". While it has been successfully used in models like T56,
it comes with additional complexity, both over the coding part and the
computational one.
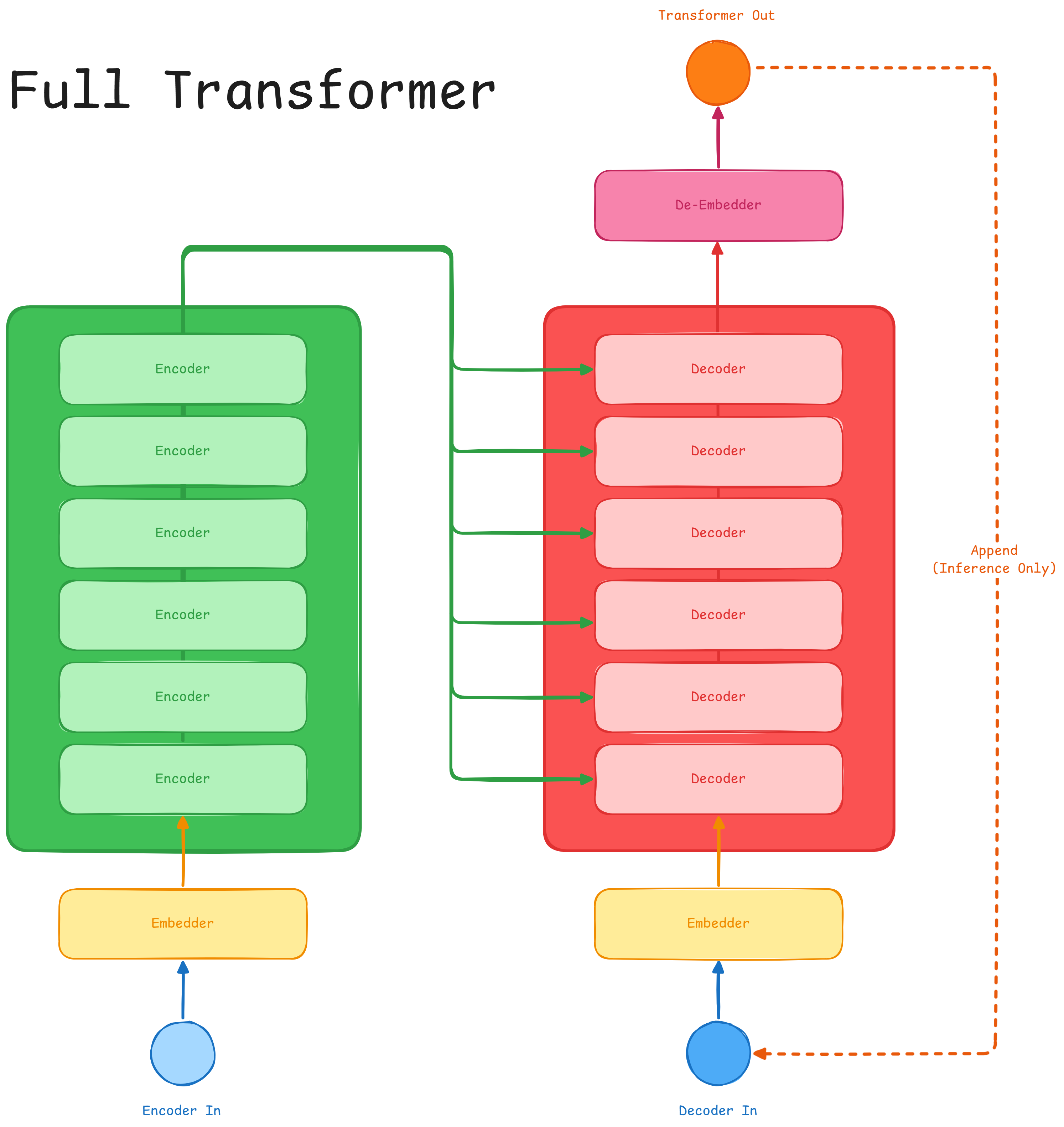
This is the basic architecture proposed in "Attention Is All You Need" 3, but nowadays has been supersided by decoder only architectures, for tasks as text generation.
Encoder Only
This architecture is done by only employing encoders at its base. A model using
this architecture is BERT7, which is capable of tasks such as Masked
Langauge Model, Sentimental Analysis, Feature Extraction and General
Classification (as for e-mails).
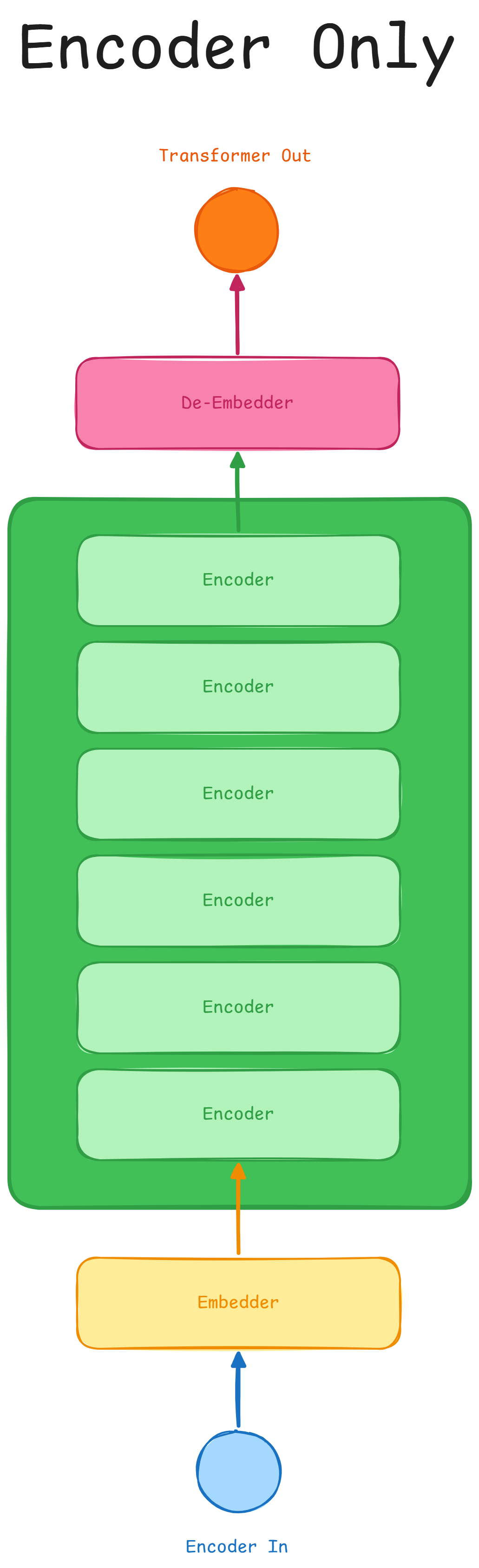
However this architecture comes at the cost of not being good at text and sequence generation, but has the advantage of being able to process everything in one step.
Decoder Only
This architecture employs only decoders, which are modified to get ridden of
cross-attention. Usually this is at the base of modern LLMS such as
GPT8. This architecture is capable of generating text, summarizing and
music (converting into MIDI format).
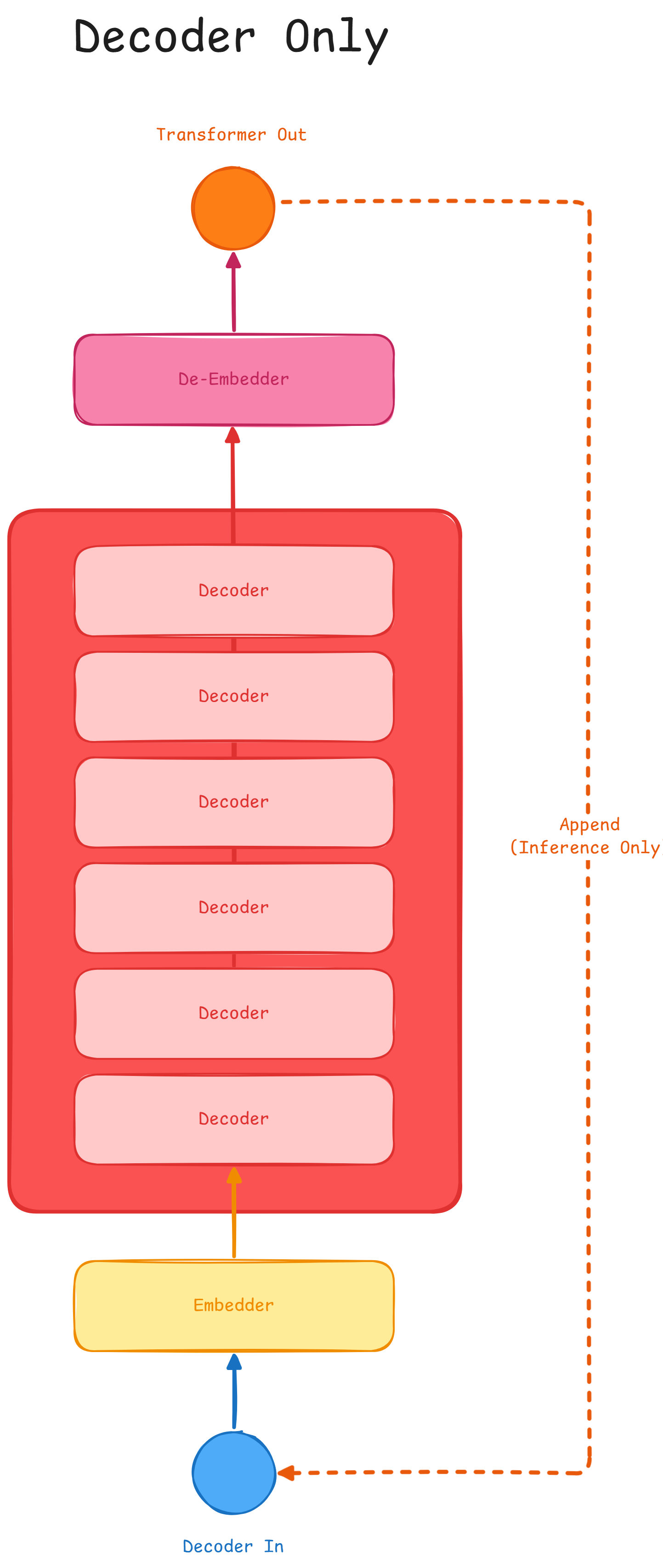
However this architecture needs time to generate, due to its autoregressive nature.
Curiosities
Note
We call
QasQuery,KasKeyandVasValue. Their names come from an interpretation given to how they interact together, like if were to search forKeyover theQueryBox and the found items isValue.However this is only an analogy and not the actual process.
-
Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention ↩︎
-
Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context ↩︎
-
ROFORMER: ENHANCED TRANSFORMER WITH ROTARY POSITION EMBEDDING ↩︎
-
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer ↩︎
-
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding ↩︎
-
Release Strategies and the Social Impacts of Language Models | GPT 2 ↩︎